Author: N. D. Baltas
CFD is by nature a computer-intensive application.
It involves the discretisation of the space and time domain, and the iterative solution of quasi-linear equations for each modelled variable in each discretised element.
Furthermore, the accuracy of the prediction increases with:
CFD is 'inherently parallel' because similar processes take place simultaneously in similar elements distributed through space, sometimes with little element-to-element interaction.
CFD codes are very suitable for porting to massively parallel systems.
The aim of the work described in this paper was to develop a generic parallel version of the PHOENICS CFD application which could be easily ported to any message-passing MIMD machine.
The main considerations for such a port was to bring a balance between achieving very good performance and retaining ease of use and code maintainability.
Good performance was achieved by restructuring parts of the code and replacing the standard Linear Equation Solver with a new Conjugate Gradient Solver. Maintainability of the code was retained by developing a single version of PHOENICS which can run on both a uni-processor systems (sequential computers) as well as on a multi-processor system (parallel computer or workstation cluster).
The standard user interface of sequential PHOENICS is the same for the parallel version and the data files are identical for the two versions. This work was performed under the ESPRIT III projects PASHA and EUROPORT.
PHOENICS is a commercially-available suite of programs widely used since 1981 for the simulation of fluid-flow, heat-transfer and chemical-reaction processes in engineering equipment and the environment.
PHOENICS consists of three main modules:
At the end of the calculation procedure, EARTH writes a file called PHI, which contains the field values of the problem domain.
PHOENICS is a general purpose-CFD code, and its modelling capabilities include:
PHOENICS solves the full differential equations governing fluid- dynamic phenomena.
The equations are solved by a finite-volume method, in which the solution domain is subdivided into grid cells bounded by continuous lines or surfaces aligned in the co-ordinate directions.
Equations for the values of each dependent variable in each grid cell are obtained by integration of the differential equations over the cell with suitable interpolation assumptions.
The linear equation is constructed for each grid point, and a set of simultaneous algebraic equations is solved for each variable.
The exception is pressure which is obtained indirectly during the solution procedure.
In the SIMPLE-like iterative schemes, the pressure-correction equation is usually derived from the continuity equation.
PHOENICS uses the SIMPLEST algorithm of Spalding[1] which is a variant of the SIMPLE algorithm of Patankar and Spalding[2].
3. PARALLELISATION OF PHOENICS
The EARTH module uses the most of the computing time and therefore it is this part of PHOENICS which is ported to the parallel computer hardware.
At the discretisation level there are several possibilities for exploiting parallelism. The most obvious is to partition the problem and distribute the subdomains to the processors available on the parallel system.
The objective is to develop a generic parallel version of PHOENICS which can be easily ported to any message-passing MIMD* machine, and to obtain satisfactory parallel efficiency, without compromising on the numerical efficiency.
To preserve maintainability of the code, a single version of PHOENICS has been developed which will be able to run on both serial and DM-MIMD* platforms by simply setting a flag (MIMD=T) to indicate that a parallel run will be made, if such a system is available.
To achieve portability of the code, generic parallel methods have been adopted which are compatible with the most features of parallel MIMD platforms and, by separating the communications from computation into a small library of functions.
The communication functions use communication primitives specific to the target system. To port the code to another system, which supports another environment, only the communication primitives have to be replaced. Parallel PHOENICS is available on most message-passing environments including PVM, MPI, PARMACS and PARIX.
The multi-EARTH approach was adopted for this port; this implies that the tasks involved in the serial EARTH are replicated over the available processors.
For the initial port, each processor had access to a complete set of input and output files as in serial PHOENICS; hence it was possible to retain the sequential data and I/O structure of the EARTH in each process.
This is the obvious approach when a parallel file system is available or when a small number of processors are involved. For a massively parallel system, where tens or hundreds of processors are used, the operating system of the host machine will be unable to support the large number of files involved (EARTH can access a large number of files at run time).
To overcome this limitation, one of the processors is made responsible for the I/O operations and the file management, therefore acting as an I/O server. This model provides the required I/O and supports distinct file structures for each subdomain. The resulting structure is portable to any message-passing MIMD system, since it does not rely on the operating system directly.
The main input operation is to read the data-file produced by the pre-processor. In this case the server reads the general data-file EARDAT, which contains information about the simulation settings as well as the description of the subdomains; then copies are passed to the other processors.
In parallel, each processor extracts an EARDAT specific to its own subdomain and then begins the solution procedure. All the input operations are handled in the same manner by the parallel system.
At the end of the solution run, each processor produces field data which are assembled by the server processor, reconstructed into one set of data for the problem and written on the disk as one PHI file.
3.3. Multi-domain link and communication
The next step in the development of the port is to provide appropriate links between the subdomains being solved in parallel by different processors.
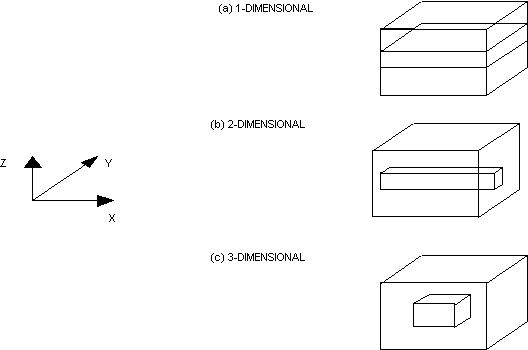
Assuming the computational grid has a regular structure, then topologically it is cuboidal in shape with NX*NY*NZ cells. Three partitioning strategies can arise from such a grid.
In the first, a one-dimensional decomposition is defined where the whole domain is divided into slabs (see (a) below) and each slab is allocated to a processor.
In the second strategy a two-dimensional decomposition is defined as shown in (b) below, and each subset of cells is assigned to a separate processor.
In the third, the three-dimensional decomposition, a cuboidal subset of cells is allocated to each processor (see (c) below).
The simplest is the 1-D domain decomposition where the domain is divided into subdomains in one direction only.
Although the 1-D domain decomposition can be applied to either x-, y- or z-direction, the most efficient for PHOENICS is the z-direction.
PHOENICS has been designed in a way that most arithmetic operations, performed during an iteration cycle (a SWEEP), are carried out for one slab (slab of NX*NY cells at constant grid index IZ), before it transfers its attention to the next slab in line.
Although PHOENICS can solve the variables in question either in a 'slabwise' or 'whole-field' manner, velocities are solved slabwise only.
This structure of PHOENICS favours the domain decomposition to take place in the z-direction and only this implementation is described here. The solution procedure is based on the SIMPLE-type algorithm where calculations involve only data associated with near neighbours in the geometric mesh.
In the case of first-order approximation (i.e. upwind, hybrid schemes) to the terms of the PDE, only the nearest neighbours are involved.
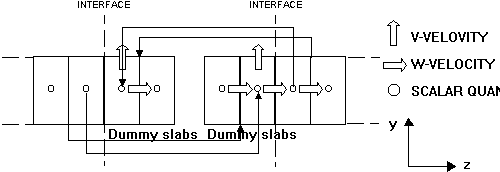
To link the subdomains together each process needs data from the adjacent subdomains. To provide each process with this information, the subdomains assigned on each processor are enlarged by adding two slabs of cells to each subdomain end.
The need for the additional two slabs is based on the staggered-grid geometry that PHOENICS uses for the velocity components. The exchange of the boundary values proceeds in a parallel manner when synchronous communication is used.
Based on a PIPE topology, each processor is consecutively numbered from 0 to NPROC-1 (NPROC is the number of processors).
During the data-exchange procedure, all the even-numbered processors first send newly computed boundary data to their odd-numbered neighbours which they only receive.
Then, even-numbered processors and odd-numbered processors switch their duties.
This parallel communication scheme, and the constant message length, ensure that the absolute time used for boundary-data communication is almost constant and independent of the number of processors involved in the parallel computation. Global data reduction is another type of communication required by Parallel PHOENICS.
This type of communication mainly occurs in the linear equation solver, where many inner-products are performed frequently and the global sum is evaluated.
The sum operation requires the exchange of small data packets between all processors and depends on the speed of the interconnecting network and on the number of associated processors.
These global operations are costly but cannot be avoided.
The global sum becomes the major bottleneck for problems of constant size and increasing number of processors.
3.4 Replacement of the Linear Equation Solver
High parallel efficiency does not guarantee a numerically efficient solution when grid-partitioning techniques are used for the parallelisation of CFD applications.
Numerical efficiency of the parallel algorithm is equally important.
Grid-partitioning schemes can be used efficiently only when the subdomains are properly coupled, so that the number of iterations required for convergence will not significantly increase compared to a single domain solution.
The most effective strategy is to couple the subdomains within the inner iterations for each solved variable; this requires a parallelisable linear-equation solver. The standard PHOENICS solver, with block-correction acceleration, is very efficient for sequential computers; but its recursive structure poses great difficulty for implementation on parallel machines.
The need for an easily parallelisable linear equation solver led to the investigation of a number of acceleration techniques based on conjugate direction methods, including the classical Conjugate Gradient [3], Conjugate Gradient Squared [4] and the Conjugate Residual method [5].
These acceleration procedures were used with a number of iterative relaxation procedures including the classical Jacobi and m-step Jacobi.
The classical Jacobi allows easy parallelisation [6] and it was used with the Conjugate Residual Method for the current implementation.
On its own, the one-step Jacobi method has a poor rate of convergence; but when combined with the Conjugate Residual acceleration, convergence rate is enhanced significantly by changing the strategy of the solution search. We want to solve in parallel the linear system:
Ax = b
where A is an n by n matrix. If M is the preconditioning matrix on each subdomain, then the solution proceeds for each subdomain as follows:
Let x(0) = initial_guess_of_the_solution
Transfer x(0) values at the boundaries
r(0) = b - Ax(0) Obtain first estimate of the residual
Solve Mxbar(0) = r(0) to obtain auxiliary vector xbar0
Lam(0) = 0
while (|r(k)|>tolerance) k=0,1....
x'(k) = x(k) +xbar(k) Compute the function vector on the
predictor step
Transfer x'(k) values at the boundaries
r'(k) = b - Ax'(k) Compute the corresponding residual
vector
if k # 0
Obtain Global Sum of the inner-products before calculating lam
lam(k) = (r'(k) - r(k),qbar(k))/(q(k),qbar(k))
Solve Mxbar(k) = r(k) to obtain auxiliary vector xbar(k)
endif
p(k+1) = xbar(k) + lam(k)p(k) Compute direction vector for the
function
q(k+1) = (r'(k) - r(k)) + lam(k)q(k) Compute direction vector
for residuals
Solve Mqbar(k+1) = q(k+1) to obtain auxiliary vector qbar(k+1)
Obtain Global Sum of the inner-products before calculating alf
alf(k) = (qbar(k+1),r(k))/(qbar(k+1),q(k+1))
x(k+1) = x(k) + alf(k)p(k+1) Compute final value of the
function vector
r(k+1) = r(k) + alf(k)q(k+1) Compute final value of the
residual vector
endwhile
All the operations described in the above algorithm can be done independently on each processor.
To determine the scalar variables alf and lam at each iteration, the inner products are done by a fan-in and then alf and lam are calculated in each domain but their values represent the whole computational domain.
3.5 The parallel SIMPLEST method
PHOENICS uses the SIMPLEST algorithm to link the hydrodynamic equations. SIMPLEST computes velocity components slab-by-slab; hence for these variables the domains cannot be coupled at the solver level.
This requires the velocity components to be exchanged at the end of each outer iteration.
This makes the multi-domain solution slightly different, compared to the one-domain solution, but the communication overheads are reduced.
Overall the performance of the multi-domain SIMPLEST, in terms of convergence rate and stability of convergence, is sufficiently like the serial algorithm and existing simulations can be moved from the serial machine to the parallel, and vice versa, without any additional effort. The parallel SIMPLEST has been implemented as follows:
The parallel-SIMPLEST algorithm is illustrated below, for the 1-D domain decomposition.
For the I/O server node
READ and DISTRIBUTE geometry specifications and other parameters For all other nodes
RECEIVE geometry information and other parameters
Do for NSTEPS time-steps
Do until convergence or maximum number of iterations reached
Do for all(x,y)-slabs on this node in sequence Calculate sources, coefficients and solve for new V (2D-Solver) Calculate sources, coefficients and solve for new U (2D-Solver) Calculate sources, coefficients and solve for new W (2D-Solver)
Exchange values for U, V, W at subgrid boundaries between processors Compute global residuals for U, V, and W Assemble pressure correction equation and solve (3D-Solver) Compute global residual for pressure Assemble equations and solve for other variables: ke, ep, h (3D-Solver)
For the I/O server node RECEIVE and PRINT results from this and other nodes
For all other nodes SEND results to the server
End
3.6 Global convergence monitoring
Convergence is monitored by combining the partial residuals (for each variable) from each subdomain, to give a global estimate for the entire problem and comparing it to the prescribed convergence criterion.
The prescribed convergence criterion is common for each domain and it as been broadcast by the server during the initialisation process. Residual values are then computed independently on each subdomain just as in the serial EARTH.
For the parallel version, similar estimates of the residuals are made on each subdomain, excluding the dummy cells.
When local residuals have been estimated, they are broadcast to the server processor and in the process the global sum is obtained for the entire domain.
The global residual is then broadcast back to the other processors and the convergence check is performed by each processor independently.
This convergence test is performed every outer iteration but it is possible to reduce communication cost by less-frequent checks.
A number of test cases were benchmarked using sequential PHOENICS running on a "high-end" workstation, and parallel PHOENICS running on various parallel platforms.
The objective of these benchmarks was to evaluate the performance of parallel architectures against a sequential workstation.
In some cases a direct comparison of the performance of the parallel machines can be made. However, note that Parallel-PHOENICS runs under different implementations on the parallel platforms, i.e. PARIX, PVM, PVMe and MPI. Two test cases were considered:
Different grid sizes were adopted for each problem.
The Table below summarises the test cases considered.
CASE NO. CASE TITLE GRID SIZE: NX*NY*NZ NO OF SWEEPS
1 Ship (Coarse grid) 15x15x64 400
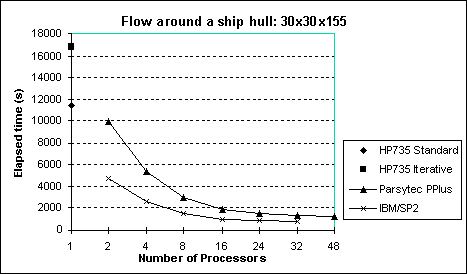
2 Ship (Fine grid) 30x30x155 400
3 Buildings (Scaled) 30x20x[24 to 1152] 300
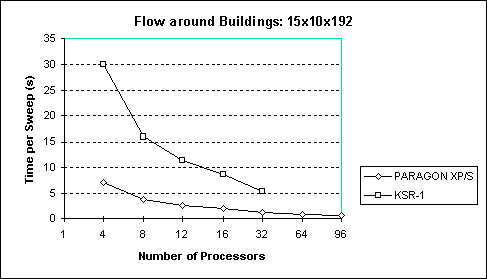
4 Buildings (Fixed grid) 15x10x192 150
In this case, the solution domain is a cylindrical quadrant in which the hull half-section occupies the region near the axis.
The South boundary (negative y-axis) represents the hull surface and the East boundary (positive x-axis) represents the waterline. The computational domain starts and ends far from the ship (1 to 1.5 ship-lengths).
Two grid sizes were used for the computations, 15x15x64 and 30x30x155 (see figure below).
Only the finer grid can produce results that simulate actual physical behaviour.
For both cases the flow is turbulent, viscous and steady. PHOENICS solves for pressure (P), the velocities (U, V, W) and the turbulence variables KE and EP.
The k-e model is used for turbulence modelling. The flow domain is made up from an inlet (fixed mass flow and axial velocity of 1.89 m/s) and outlet (fixed mass, 2nd derivative of axial velocity is zero) and the two symmetry planes.
A free stream boundary condition is applied to the outer boundary of the domain. In the case of the ship-hull, a fixed wall boundary condition is applied.
A turbulent wall condition (including wall functions) is also implemented. For the solution procedure the 'whole-field' option is used for the pressure (P), but the 'slabwise' or 'parabolic' option is used for the other variables.
Two linear equation solvers were used, the 'standard' PHOENICS solver (Stone's-like derivative) and an 'iterative' solver (conjugate gradient variant with diagonal preconditioning).
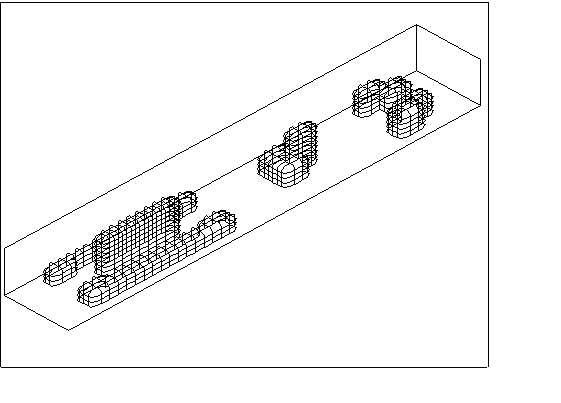
4.2 Flow around a group of Buildings
This case was used to test the scalability of the code.
Adopting a 3-D cartesian grid, the problem has been scaled-up (in the z-direction) as the number of processors increased.
The grid partitioning was done in the z-direction.
The flow is steady and laminar. PHOENICS solves for pressure (P) and the velocities (U, V, W).
The arrangement of the buildings is shown below.
For the sequential tests, an HP 9000/735 with 144 Mbytes of memory running at 99 MHz clock-speed, was used.
A summary of the parallel architectures used is shown in the Table below.
ARCHITECTURE ENVIRONMENT Parsytec PowerPlus PARIX DEC Turbolaser PVM DEC 7760 PVM IBM/SP2 PVMe INTEL PARAGON XP/S MPI KSR-1 MPIFor all the cases tested, the convergence history of the sequential and the parallel version did not show any major differences.
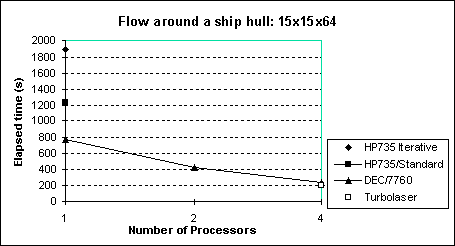
This test case was benchmarked on a HP735 and DEC Alpha Servers (7760 and Turbolaser). Results from the Standard LES and the Iterative (conjugate gradient) solver are also presented in the figure below.
It is seen that the iterative solver is slower (40%) due to the extra floating-point operations and the fact that it operates in double- precision.
There are also overheads associated with the conversion from double- precision to single-precision and vice-versa.
From the same figure it is clear that the DEC Servers are much faster than the HP735 (even when it runs on one processor), and reasonable speed-up can be achieved with 4 processors, although this case is too small for parallel systems.
For this test case it was not possible to perform the benchmarking on one-node Parsytec or one-node IBM/SP2, due to the limited memory per node.
Again the Iterative solver is substantially slower than the direct solver (see figure below).
However, 2 Parsytec nodes outperform the workstation (using the fastest Serial LES). Substantial speed-ups are achieved using up to 16 processors.
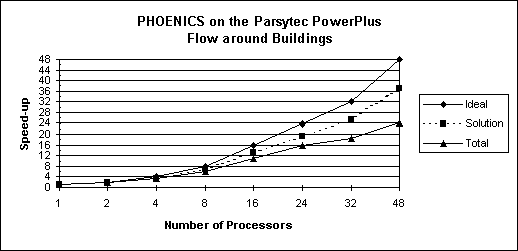
CASE-3: Buildings (Scaled problem)
The scalability of the code was examined by increasing the grid size as the number of processors increased. The speed-up results are shown in the figure below.
The 'Solution' curve is the speed-up obtained from measuring the solution time (including communication overheads), but excluding the time taken to write the results to a file.
The 'Total' curve was calculated from the 'wall-clock' times obtained.
The 'Total' curve will approach the 'Solution' curve if a parallel file system was available and more nodes had access to disks and were writing to a file.
Note that on these tests only one node (I/O server) had access to a disk, resulting to a bottleneck as the other nodes were transmitting their data to the I/O server for output.
CASE 4: Buildings (Fixed grid)
For this test case, an INTEL Paragon XP/S and a Kendall Square Research (KSR-1) at Oak Ridge National Laboratory [7], were used.
The times presented below are from one iteration of the program solution phase.
It is clear that the Paragon outperforms the KSR-1!
A generic port of PHOENICS has been developed for MIMD parallel computers based on grid partitioning techniques and message-passing libraries such as PVM, MPI and PARIX.
A parallel file system is required when more than 16 processors are used.
The aim of the port was to bring a balance between performance, maintainability and ease of use.
The resulting code can be run on sequential computers as well as parallel MIMD computers and supports the original PHOENICS functionality.
Satisfactory speed up factors have been demonstrated with parallel efficiencies, for large and complex CFD cases, approaching 90%.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}