See also:
How to run Parallel PHOENICS 3.1
and
An earlier report on comparative performance
* CHAM has developed a generic parallel version of the PHOENICS CFD code which can easily be ported to any message-passing MIMD machine providing a balance between achieving very good performance and retaining ease of use and code maintainability.
* Parallel PHOENICS has already been used by major industrial, research and academic organisations, e.g., STATOIL, Honda R&D and DRA. Parallel computing can significantly improve the competiveness of business in many different ways:
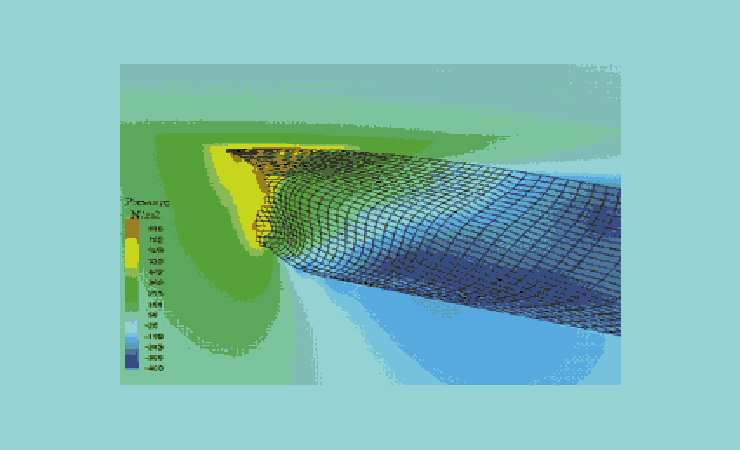
A parallel-PHOENICS simulation of flow around a ship's hull: the pressure field
CFD is well suited to parallel processing and parallel computers have become the main platform for the computation of complex and time-consuming problems.
To take advantage of the increased power of the latest generation of parallel computers, CHAM have developed a generic parallel version of its general purpose CFD code, PHOENICS, to run on most multi-processor computers, work-station clusters and recently PC-clusters.
PHOENICS was the first general-purpose CFD code to be ported generically to massively-parallel computers. Porting is based on domain decomposition, where the computational domain is divided into sub-domains.
The computational work related to each sub-domain is then assigned to its own processor. A modified version of the PHOENICS solver (EARTH) is replicated over all available processors and runs in parallel, exchanging boundary data at appropriate times.
The PHOENICS pre- and post-processors (SATELLITE and PHOTON) run in sequential mode.
Rapid convergence of the solver is achieved due to the efficient sub-domain coupling, hence no additional sweeps are required.
The processors communicate using the standard message-passing protocols (i.e. PVM or MPI) as used on all major parallel platforms, therefore the code can run on any parallel machine that supports PVM or MPI.
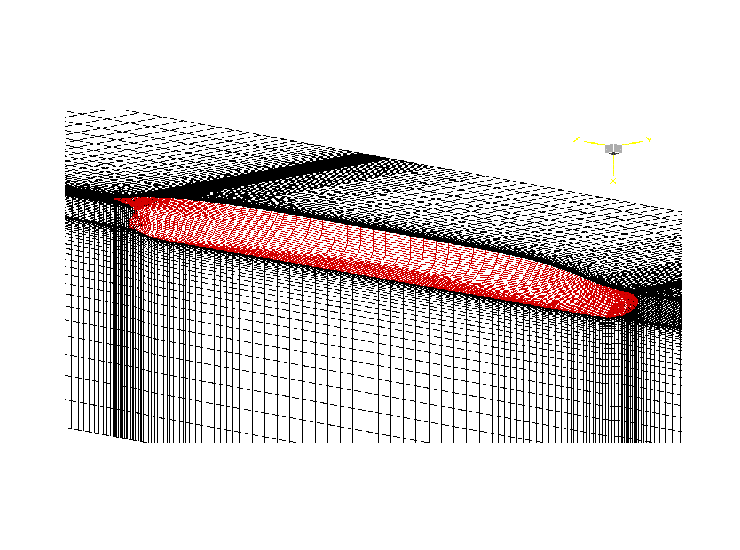
Another ship-simulation picture; the grid
The efficiency depends on the size and complexity of the case (the more complex the better). Even with simple cases with increasing grid size, speed-ups of 5, 8, 14 and 23 (respectively) are achieved compared wit the same cases run on high-end serial workstations.
The simulation results matched those on serial runs, and from the user's viewpoint, the procedure is no different from running standard PHOENICS.
Benchmarking of Parallel PHOENICS has been completed on three classes of parallel platforms.
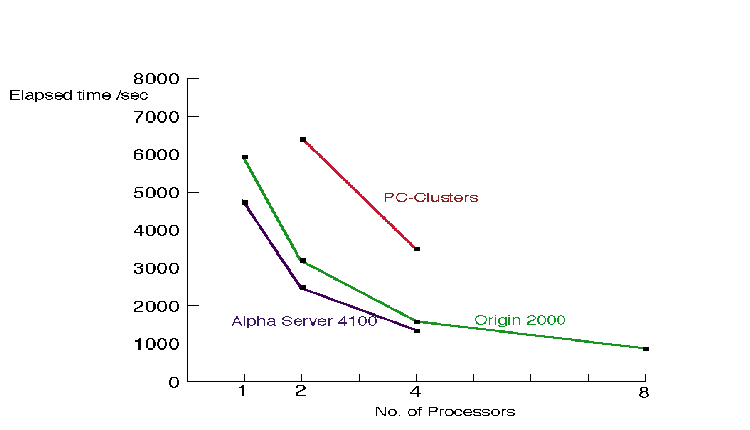
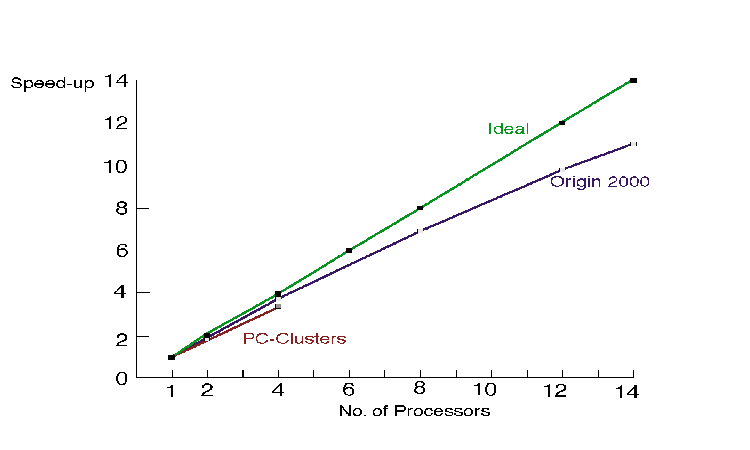
Detailed performance figures are demonstrated in the simulations of the flow around a ship hull for different platforms. In the following figures is shown:
1. Reduction of elapsed time with increasing number of processors
2. Performance is almost linear with the number of processors
PHOENICS has now been ported and benchmarked on a wide range of parallel machines, in fact all MPP and SMP computers that support message passing (MPI or PVM) can now run parallel PHOENICS.
Systems Benchmarked:
Parallel PHOENICS is also available on the following systems:
{kind=link}
{kind=link}
{kind=link}
{kind=link}